Bringing more causality to analytics
Sean J. Taylor, Chief Scientist at Motif Analytics
I’ve spent a lot of my career trying to convince folks that taking causality seriously is the most reliable way to drive business impact with data. Models, estimates, and analyses that we can’t interpret causally tend to answer particularly unhelpful questions. When we build a model to predict which users are going to churn, what we are really looking for is a model that tells us why they are churning, or even better: how can we prevent them from churning? While counting things reliably and building reproducible reporting is indisputably helpful to businesses, data can drive the most impact when it changes people’s minds about what to do, and a causal analysis is designed to do just that.
In this post I want to share a vision for how we can bring causality to the forefront of analytics practice. The key idea is combination of using richer data (sequence data, straight from your favorite logging framework) and new tools that better leverage human domain knowledge in the analysis process. A human-in-the-loop process to iteratively discover and critique potential cause-effect relationships will maximize the useful discoveries we can make with our analytics data.
Experiments are the tip of the causal iceberg
Rigorous thinking about causality is widely applied in one special setting: experiments, where we randomly assign product or algorithmic changes, represent a special case where the most straightforward analysis is the causal analysis. There can be challenges in interpreting experiment results even with large samples and good experimental designs, but gradually most people in modern product, engineering, and data organizations are taking their first steps into the causal inference world.
The problem with experiments is that they answer only a very small slice of causal questions we have, and for the remainder we are given little guidance on how to approach answering them. People seem to be broadly aware they need to be concerned about confounding, they’ll recite “correlation is not causation,” draw diagrams of Simpson’s paradox, and draw causal graphs to point out identification problems. Unfortunately, the commonly given advice is often not constructive to practitioners — it tells us what to worry about without giving us a path forward.
Types of causal questions
We start by broadening the set of causal questions we ask. Many teaching examples start with simple questions like “does smoking cause cancer?” which is obviously quite useful to know but presumes we have already chosen a cause-effect pair to evaluate and have already measured them. There is a larger set of useful causal questions than “does X cause Y?” and they come up all the time!

For either cause or effect we may know the variable of interest in advance or not, yielding four possible types of causal questions. I’ll discuss each quadrant briefly:
- Testing: Experiments occupy the bottom left quadrant: we know the cause (our product change) and the effects we want to look at (our metrics). These questions are often about estimating the strength of the relationship between the cause and effect so we can evaluate whether something is a success.
- Explanation: Often called “root-cause analysis,” a frequent analytics activity is to notice an effect in the data (e.g. a drop in an important metric) and then conduct a search for the cause.
- Characterization: In some cases we know about the cause because some change was introduced (either by us or externally), and we would like to understand what the consequences are. It can be valuable to determine if anything unexpected has happened to uncover unforeseen costs or benefits.
- Discovery: The most open-ended causal questions pertain to whether cause-effect relationships exist that we have not considered, but that matter to our business. There may be things we are doing that we haven’t studied which have hidden consequences that are good or bad for our business in the long-term.
Exploring a broader cause-effect space
From the diagram above we can see that one way to broaden our application of causal modeling involves the capability to explore relationships between these (currently) “unknown” variables. Known causes and effects are served by existing metrics and experimentation platforms, where the hypothesis space (potential cause-effect relationships) can be articulated in advance: causes are experiments we’ve run and effects are our user-level metrics. But clearly unknown cause-effect relationships are looming in our data — what makes them “unknown” to us?
Potential variables remain “unknown” when we haven’t thought to define and measure them or because it’s too difficult to do so. We should be pretty interested in what more we can learn if we expand the set of variables we can model. We lack a means to rapidly prototype complex transformations to our data, and rely on data engineers plus many layers of tools to reliably compute the metrics we’ve defined. How can we make this process more agile, letting us expand the set of directions we can point our modeling lens? Especially in the exploratory phase before a metric is ready to be productionized?
Anyone who has analyzed enough data understands the limitations of existing approaches, particularly using SQL to do so. I am not going to critique the SQL ecosystem or all the very impressive advancements we’ve gotten to enjoy recently. The set of SQL-based analytics tools is blossoming and becoming easier, faster, and smarter.
But it remains challenging to write queries that don’t align with the assumptions of the relational model. In particular, finding patterns in sequence data (i.e. ordered log events grouped by user) remains a challenge to implement efficiently and succinctly. The query engine we’ve built at Motif Analytics is based on pattern-matching ideas from regular expressions and is designed from the ground up to make it easy to find “motifs” that capture potential causes and effects.
Example
Say you work on an e-commerce app and you are interested in identifying opportunities to improve how many browsers turn into buyers. You wonder whether users are finding compelling items, so you search for a new pattern that captures whether a user’s sequence data includes landing on a product page, scrolling down, and spending at least 30 seconds on the page. Querying for this pattern creates a new “effect” you can study, and now we can start to think about potential causes. You could also quickly redefine this pattern, perhaps removing the scrolling requirement or varying the window (maybe 30 seconds is too short or long).
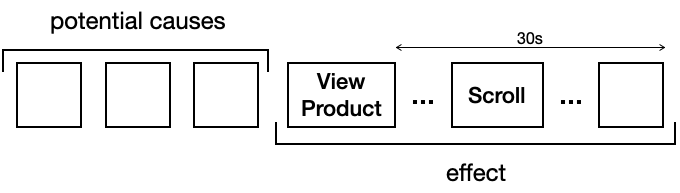
When we’re looking for potential causes in the real world, we often start with what happens nearby and immediately before the observed effect. Similarly with a sequence of user-generated events, we start exploring potential causes by focusing on the events that occur before the “found interesting product” motif. You notice that these successful events are often closely preceded by a search event. You measure that sequences with searches are less common than you’d expect and notice that your search box is not easy to find on the home page. You propose a project to make search a more prominent feature on your app. It’s a low cost change and your analysis includes a total opportunity sizing:
[Effect on total searches] * [Found Products / Search] * [Revenue / Find Product]
where the last two terms can be estimated using conditional probabilities with sequences. This cost-benefit analysis motivates a small project culminating in an A/B test. The test can validate your hypothesis that search usage causes users to find more interesting products — the random assignment in your test is a valid instrument for search behavior and an instrumental variables analysis is possible.
One way to think of this is as a re-envisioned funnel analysis — we should be able to shift our analytical lens between upstream causes and downstream effects, leveraging the sequential nature of the data as a useful heuristic for which is which. Estimating conditional probabilities on motifs within sequences — and counterfactuals for those probabilities — captures a wide swath of analytics tasks.
The problem of confounding
If you’re reading this and you’re anything like me, alarm bells are going off: what makes any of this “causal”? The correlation you noticed in the example could easily have been driven by an unobserved confounder, a case of omitted variable bias. There are plausible alternative explanations, for instance very interested buyers may do more of both things: using search and spend time reading about products. We have a causal DAG with an unobserved confounder (dashed box):
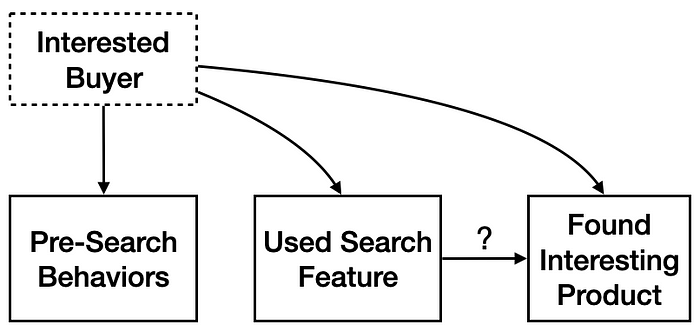
The promise of sequences is the rich set of behaviors we observe before the “treatment” variables may provide information about how interested a buyer really is. We can attempt to estimate the causal effect of using the search feature by adjusting (often called “controlling”) for variables that capture buying interest: usage of other features, user time on site, previous purchases, even highly specific things like scrolling or time spent on product pages previously.
We can adjust our estimate of the effect of using the search feature by comparing users who search to only those with similar pre-search behaviors. This provides a less biased comparison, and more credible estimate of the potential effect, as we see in the figure below. Adjusting for confounding can be an iterative, human-in-the-loop process, allowing users to be critical of raw correlations and rule out confounding due to reasonable counter-hypotheses by constructing and adding new variables to adjust for.
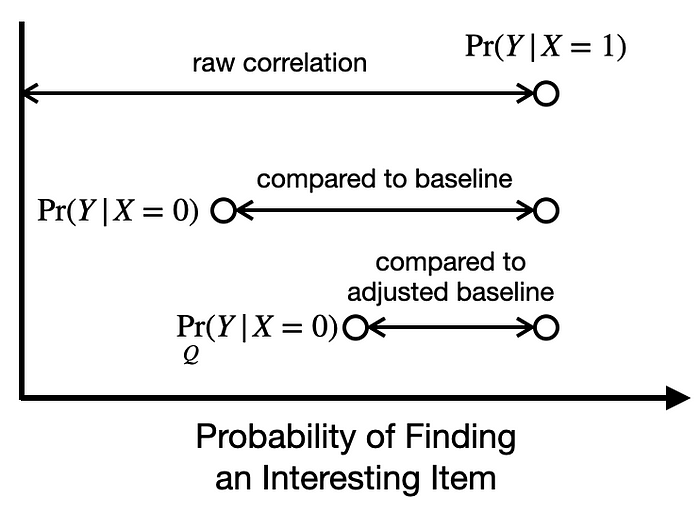
Whether an analysis is causal or not is not a binary property, and a “more causal” analysis where we rule out potential confounders through adjustment will be less wrong (lower error). Better (likely more conservative) estimates of effects can facilitate a better prioritization process by being more honest about costs and benefits.
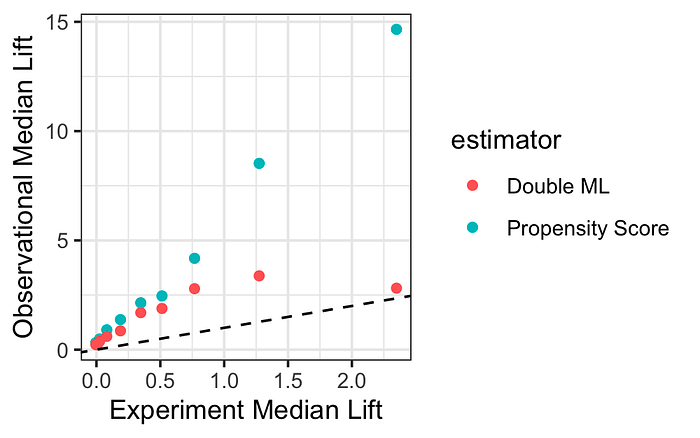
Observational (non-experimental) estimates of cause-effect relationships, though biased, can be informative about effects observed in real experiments when adjusted properly [1],[2],[3]. For instance one recent paper compared results for 663 ads experiments with estimates using non-randomized comparisons adjusted in various ways. Even after adjustment the bias from confounding is large (all estimates are above the dashed line), but the overstatement is systematic — larger observational estimates are associated with larger experimental estimates.
The ability to distinguish ideas that will generate the largest test results is an important part of the empirical product-improvement process. Discovering and prioritizing ideas to test is highly complementary to running and analyzing those tests. Better tools for generating hypotheses through structured exploration lead to more promising and successful hypothesis tests. The flowchart below illustrates an ideal version of the process by which a business can be improved holistically through causal thinking: starting with generating causal hypotheses, turning them into interventions (new causes) to be prioritized for test, and then running and analyzing randomized experiments.
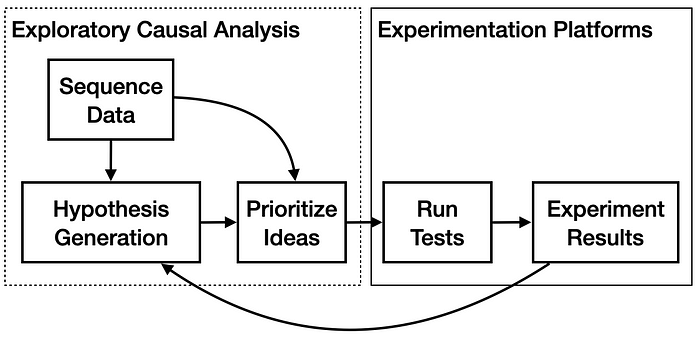
We can think of the first half of this process as “exploratory causal analysis,” a phase that helps create a priority queue of promising improvements to test. Hypothesis generation involves theory-guided analysis of sequence data and past experiment results. Ideas based on hypotheses can be prioritized by rigorously estimating overall impact of improvements. Sequence data provides additional information to two crucial phases.
Conclusion
For much of my career, I have been wondering how ideas from causal inference can be more useful to practitioners working on real-world analytics problems. I am thrilled to have joined Motif Analytics to work on this full-time, and we’re already starting to make promising progress on this. I think the answer lies in a combination of better data, more powerful tools designed to let human domain knowledge shine, and a thoughtful relationship with existing analytics tools such as A/B tests.
Motif’s expressive sequence analytics tool provides a step-function improvement in how quickly we can perform complex correlational analyses. Users can iteratively create new variables to measure based on pattern matching and bring more concepts from unknown (or unconsidered) and into their analyses. Behavioral motifs have a natural cause-effect ordering, giving us a starting point for causal modeling, and a path toward reducing confounding through careful adjustment for prior behaviors. We believe many products and services will benefit from exploratory causal analysis, where analysts iteratively discover and stress-test potential causal relationships in their data. Motif’s approach will bring the best insights and opportunities to product managers and designers, who need more help from analytics in finding the most troublesome problems and promising paths forward.
If this sounds interesting or exciting to you, please get in touch! We’re looking for early partners who’d like to try our product, as well as engineers and designers focused on interactive data visualization.